论文链接:Side Adapter Network for Open-Vocabulary Semantic Segmentation
代码链接:https://github.com/MendelXu/SAN
作者:Mengde Xu,Zheng Zhang,Fangyun Wei,Han Hu,Xiang Bai
发表单位:华中科技大学、微软亚洲研究院
会议/期刊:CVPR2023 Highlight
一、研究背景

ImageNet 上的分割结果。对于每个图像,将其类别与 coco 类别结合起来作为推理过程中的词汇表,并且仅可视化注释类别的掩码
现代语义分割方法依赖于大量标注数据,但数据集通常只包含数十到数百个类别,数据收集和标注成本高昂。近年来,大规模视觉-语言模型(如CLIP)在图像分类任务中取得了巨大成功,但在像素级别的语义分割中应用这些模型面临挑战,因为这些模型的训练侧重于图像级别的对比学习,它学习到的表示缺乏语义分割所需的像素级识别能力。弥补表示粒度差距的一种解决方案是在分割数据集上微调模型。然而,分割数据集的数据量远小于视觉语言预训练数据集,因此微调模型在开放词汇识别上的能力常常受到损害。
将语义分割建模为区域识别问题绕过了上述困难。早期尝试采用两阶段训练框架。
在第一阶段,训练一个独立模型来生成一组蒙版图像作物作为蒙版建议。
在第二阶段,使用视觉语言预训练模型(例如 CLIP)来识别蒙版图像裁剪的类别。然而,由于掩模预测模型完全独立于视觉语言预训练模型,它错过了利用视觉语言预训练模型强大特征的机会,并且预测的掩模图像裁剪可能不适合识别,这会导致模型笨重、缓慢且性能低下。
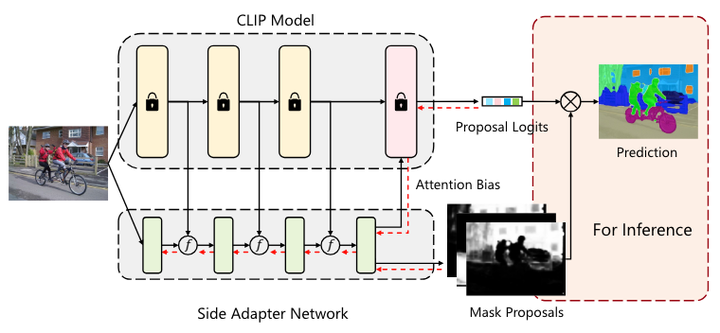
SAN 概述
为了实现这一目标,提出了一个新的框架(上图所示),称为侧适配器网络 (side adapter network, SAN)。由于端到端训练,它的掩模预测和识别是 CLIP 感知的,并且由于利用了 CLIP 的特性,它可以是轻量级的。
红色虚线表示训练期间的梯度流。在框架中,冻结的 CLIP 模型仍然充当分类器,并且侧适配器网络生成掩码提案和注意偏差,以指导 CLIP 模型的更深层来预测提案明智的分类逻辑。在推理过程中,将 mask proposal 和proposal logits 结合起来,通过 Matmul(矩阵乘法函数)得到最终的预测。
二、整体框架
本文提出了一种新的开放词汇语义分割框架——Side Adapter Network (SAN)。该方法将语义分割任务建模为区域识别问题。SAN附加在冻结的CLIP模型上,具有两个分支:一个用于预测掩码提案,另一个用于预测应用在CLIP模型中的注意力偏差,以识别掩码的类别。整个网络可以端到端训练,使附加的侧网络能够适应冻结的CLIP模型,从而使预测的掩码提案对CLIP感知。
作者证明这种解耦设计提高了分割性能,因为用于 CLIP 识别掩模的区域可能与掩模区域本身不同。为了最大限度地降低 CLIP 的成本,进一步提出了单前向设计:将浅层 CLIP 块的特征融合到 SAN,并将其他更深的块与注意力偏差相结合以进行掩模识别。
因为用于 CLIP 识别掩模的区域可能与掩模区域本身不同的理解:CLIP模型主要是通过对比学习在图像级别进行训练的,其学习到的特征更偏向于全局或大范围的图像特征,而不是具体的像素级别特征。当CLIP模型应用于掩模识别时,它的注意力机制可能会关注到一些与掩模区域有重叠但并不完全一致的区域。这种不完全一致性是因为CLIP的注意力机制可能会将注意力分散到整个图像中一些相关的部分,而不仅仅是掩模的边界或内部区域。
假设有一张图像,其中有一只狗在草地上。CLIP模型可能会关注到整只狗以及周围的草地作为特征进行分类,而语义分割任务仅需要标注出狗的具体轮廓区域。这时,CLIP的识别区域(整只狗和部分草地)与实际需要的掩模区域(狗的轮廓)并不完全一致。
出于公平性和可重复性的目的,该研究基于官方发布的 CLIP 模型。重点关注已发布的 ViT CLIP 模型,因为视觉 Transformer 事实上已经取代 ConvNet 成为计算机视觉社区的主导骨干网,并且为了概念的一致性和简单性,侧适配器网络也由视觉 Transformer 实现。
准确的语义分割需要高分辨率图像,但已发布的ViT CLIP模型是针对低分辨率图像(例如224×224)设计的,直接应用于高分辨率图像,性能较差。为了缓解输入分辨率的冲突,在 CLIP 模型中使用低分辨率图像,在侧适配器网络中使用高分辨率图像。作者证明这种不对称输入分辨率非常有效。此外,还探索仅微调 ViT 模型的位置嵌入并注意改进。
三、核心方法 Side Adapter Network
3.1 架构介绍
Side Adapter Network (SAN) 是一个端到端的框架,旨在充分利用CLIP模型在开放词汇语义分割中的能力。SAN由一个轻量级的视觉Transformer实现,可以利用CLIP的特征,并且有两个输出:掩码提案和用于掩码识别的注意力偏差。这些注意力偏差应用于CLIP的自注意力机制,以识别掩码提案的类别。
在实践中,将浅层 CLIP 层的特征融合到 SAN 中,并将注意力偏差应用于更深的 CLIP 层以进行识别。通过这种单前向设计,可以最大限度地降低 CLIP 模型的成本。
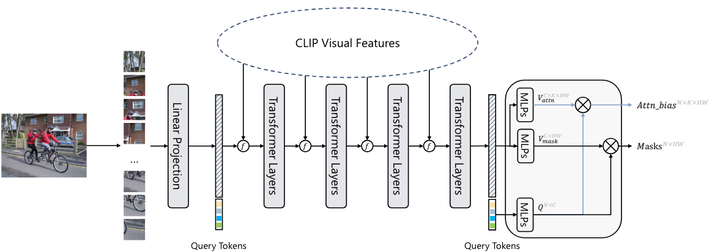
SAN的详细架构
-
输入图像:输入图像被分割成16×16的图像块,每个块通过线性嵌入层投射为视觉tokens。
-
视觉tokens与查询tokens:这些视觉tokens与N个可学习的查询tokens连接在一起,并输入到随后的Transformer层中。
-
输出:SAN有两个输出:掩码提案和用于掩码识别的注意力偏差。查询tokens和视觉tokens分别通过两个独立的3层MLP(多层感知器)投射为256维度的向量,用于生成掩码提案和注意力偏差。
投影查询标记可以表示为 ,其中N是查询标记的数量,默认等于100。投影视觉标记可以表示为
,其中H和W是输入的高度和宽度图像。最后的预测mask由Q mask和V mask的内积生成:
其中, ,产生注意力偏差类似于掩模预测。查询标记和视觉标记也由 3 层 MLP 投影,表示为
,其中 K 是 ViT CLIP 的注意力头数量。通过内部生成Q attn和V attn,得到了注意力偏差:
其中, ,此外,如果需要,注意力偏差将进一步调整为
,其中h和w是 CLIP 中注意力图的高度和宽度。在实践中,Q mask和Q attn可以共享,并且注意力偏差将应用于CLIP的多个自注意力层中,即偏差用于不同的自注意力层中。
掩模预测和识别的解耦设计背后的动机很直观:用于在 CLIP 中识别掩模的感兴趣区域可能与掩模区域本身不同。
3.2 Feature fusion on visual tokens 视觉标记上的特征融合
在ViT模型中,视觉tokens和[CLS] token是主要的特征表示。为了充分利用CLIP模型的强大特征,SAN将CLIP模型的视觉tokens与SAN的视觉tokens进行特征融合。具体步骤如下:
-
特征重排:由于CLIP和SAN的视觉tokens数量和特征维度可能不同,首先将CLIP的视觉tokens重新排列为特征图,经过1×1卷积和重尺寸操作来调整通道维度和特征图大小。
-
特征融合:将调整后的CLIP特征图与SAN的对应特征图进行逐元素相加,从而实现特征融合。特征融合在多个层次上进行,例如在12层的ViT-B/16 CLIP模型和8层的SAN模型中,将CLIP的{stem,3,6,9}层的特征与SAN的{stem,1,2,3}层的特征融合。
3.3 Mask recognition with attention bias 带有注意偏差的掩模识别
原始的CLIP模型只能通过[CLS] token进行图像级的识别,为了在CLIP模型中实现精确的掩码识别,SAN引入了注意力偏差,这些偏差用于指导CLIP模型的[CLS] token在感兴趣区域进行识别。
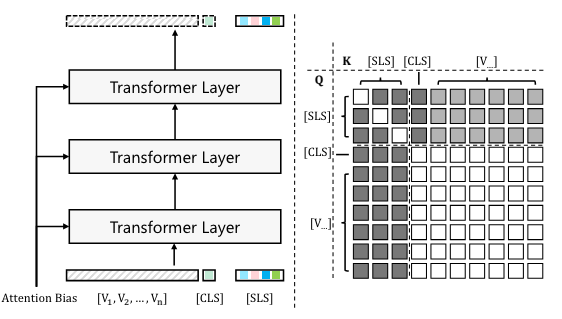
在 CLIP 中使用注意偏差来预测掩模的图示
左图创建一组 [SLS] 令牌(即影子 [CLS] 令牌副本)并将其应用于 CLIP。这些[SLS]令牌在注意力偏差的影响下更新。 右图该图显示了不同类型的令牌如何相互作用。方块的颜色表示query token和key token之间的关系:黑色表示query没有被key更新,白色表示query可以正常被key更新,灰色表示在attention的作用下query可以被key更新偏见。
过程总结:
-
生成[SLS] tokens:创建一组[CLS] token的影子副本([SLS] tokens),这些副本在更新时仅受视觉tokens的影响,而不会反过来影响视觉tokens或[CLS] tokens。
-
添加注意力偏差:在计算注意力时,将预测的注意力偏差Bk添加到注意力矩阵中,从而引导[SLS] tokens的特征逐渐适应掩码预测。
-
类别预测:通过比较[SLS] token与CLIP文本嵌入的类别名称之间的距离或相似度,轻松获得掩码的类别预测。
在计算注意力时,预测的注意力偏差 Bk 被添加到注意力矩阵中,从而引导[SLS] tokens的特征逐渐适应掩码预测。公式如下:
其中,l 表示层数,k表示第 k个注意力头,Q[SLS]=Wq X[SLS]和 V[SLS]=Wv X[SLS] 是[SLS] tokens的查询和value嵌入,Kvisua l=Wk Xvisual 是视觉tokens的键嵌入,Wq,Wk,Wv 是查询、键、value嵌入层的权重。
在原始设计中,计算复杂度为:
Tvisual 是视觉tokens的数量,T[CLS] 是[CLS] token的数量(通常为1),T[SLS] 是[SLS] tokens的数量。
这个计算复杂度考虑了所有类型的tokens,并假设它们都通过屏蔽自注意力层(masked self-attention layer)进行更新。具体来说,每个token与所有其他token进行交互,导致了二次复杂度。
为了降低计算复杂度,作者提出使用交叉注意力(cross-attention)来更新[SLS] tokens。交叉注意力与自注意力共享嵌入权重,但只涉及特定类型的token之间的交互。这使得计算复杂度降低为:
随着注意力偏差的应用,[SLS] tokens 的特征逐渐演化以适应掩码预测。掩码的类别预测通过比较[SLS] tokens和CLIP文本嵌入的类别名称之间的距离或相似度来获得:
其中 C 是类别数量,N 是查询tokens的数量。
3.4 Segmentation map generation
最后,结合掩码提案 和掩码的类别预测
,通过矩阵乘法生成最终的分割图 S:
其中, 。
为了训练模型,mask生成通过dice损失L mask_dice和二元交叉熵损失L mask_bce进行监督。mask模识别通过交叉熵损L cls进行监督。总损失为:
损失权重𝜆1、𝜆2、𝜆3分别为 5.0、5.0 和 2.0。 通过端到端训练,侧适配器网络可以最大限度地适应冻结的CLIP模型,因此掩模建议和注意偏差是CLIP感知的。
四、实验结果
在 6 个数据集上进行了实验:COCO Stuff、ADE20K-150、ADE20K-847、Pascal Context-59、Pascal Context-459 和 Pascal VOC。按照常见的做法,所有模型都在 COCO Stuff 的训练集上进行训练,并在其他数据集上进行评估。
-
COCO Stuff:它包含 164K 图像和 171 个注释类,分为训练集、验证集和测试集,分别包含 118K、5K 和 41K 图像。在实验中,默认使用完整的118K训练集作为训练数据。
-
ADE20K-150(ADE-150):它是一个大规模场景理解数据集,包含 20K 训练图像和 2K 验证图像,总共 150 个注释类。
-
ADE20K-847(ADE-847):它具有与 ADE20K-150 相同的图像,但有更多注释的类(847 个类),这对于开放词汇语义分割来说是一个具有挑战性的数据集。
-
Pascal VOC(VOC) :Pascal VOC 包含 20 类语义分割注释,其中训练集和验证集分别包含 1464 个和 1449 个图像。
-
Pascal Context-59:它是一个用于语义理解的数据集,包含 5K 训练图像、5K 验证图像以及总共 59 个带注释的类。
-
Pascal Context-459:它具有与 Pascal Context-59 相同的图像,但有更多注释的类(459 个类),这也广泛用于开放词汇语义分割。
Dataset Analysis:为了澄清并有利于对开放词汇能力的理解,作者通过计算其他数据集和训练数据集 COCO Stuff 之间的类别相似度来进行简单的分析,结果显示在表1。
-
提取文本嵌入:使用预训练的CLIP模型,将每个数据集的类别名称转换为文本嵌入向量。
-
计算余弦相似度:对于每一对数据集,计算其类别嵌入向量之间的余弦相似度。具体来说,对于两个类别集合A和B中的每个类别对(a, b),计算它们的余弦相似度,然后利用这些相似度计算Hausdorff(豪斯多夫,对于点集 A 中的每个点 a,找到点集 B 中距离 a 最近的点,然后在这些最近距离中取最大值)距离,作为这两个数据集之间的相似度度量。
-
生成相似度表:通过上述步骤,得到不同数据集之间的相似度,结果显示在表1中。
在五个验证数据集中,Pascal VOC和Pascal Context-59的相似度高达0.9,这意味着它们更擅长衡量视觉类别方面的域内开放词汇能力。此外,Pascal Context-459、ADE20K-150和ADE20K-847的相似度得分较低,这使得它们能够更好地评估跨领域开放词汇能力。
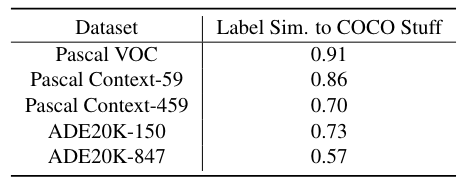
表 1:验证数据集和训练集(即 COCO Stuff)之间的标签集相似度。基于CLIP文本编码器通过Hausdorff距离和余弦相似度测量。
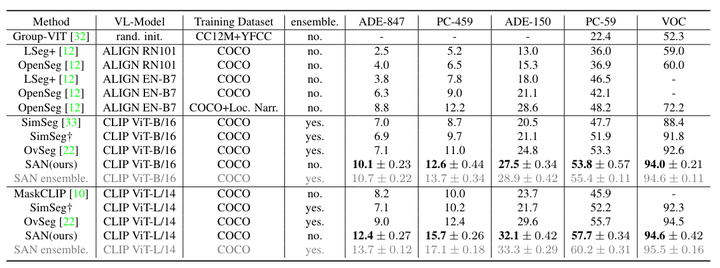
与最先进方法的性能比较。 † SimSeg [33] 在其论文中使用 COCO Stuff 的子集进行训练。为了公平比较,使用他们官方发布的代码在完整的 COCO Stuff 上重现了他们的方法。 * RN101:ResNet-101 [14]; EN-B7:EfficientNet-B7 [29]; SAN 整体。ensemble是使用集成技巧的结果,而不是默认设置。
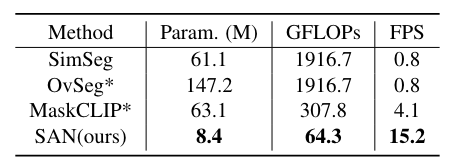
与其他方法的训练和测试效率比较。
Param.代表方法中可训练参数的总数(以百万为单位)。输入图像的分辨率为640×640。CLIP型号为ViT-B/16。 * 目前还没有可用的官方代码,按照他们论文中的描述重新实现他们的方法。 OvSeg与 SimSeg具有相似的结构,但它对整个 CLIP 模型进行了微调,从而产生了更多的可训练参数。
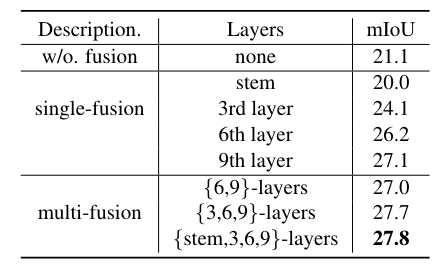
不同的特征融合策略。 ViT-B/16 的最后 3 层用于所有实验中的掩模预测。

特征融合层数量和掩模预测层数量之间的权衡
SAN轻量级的关键是利用CLIP模型的强大功能。通过实验说明了表中特征融合的重要性。 如果不融合 CLIP 功能,mIoU 将从 27.8 下降到 21.1。
此外,还注意到,融合较深层(例如第9层)的特征比融合较浅层(例如stem层)的特征要好,并且仅融合第9层的特征可以达到27.1 mIoU,比融合高+6.0 mIoU没有特征融合的基线。这一观察结果与更深层次的特征往往更具语义性的直觉是一致的。此外,与单层融合相比,融合多层特征可以进一步提高性能 +0.8 mIoU。
为了最小化 CLIP 的推理成本,采用单前向设计,即较浅的层用于特征融合,其他较深层用于mask识别,因此需要进行权衡,如上表所示。 当前9层用于特征融合,后3层用于掩模识别时,性能最佳。
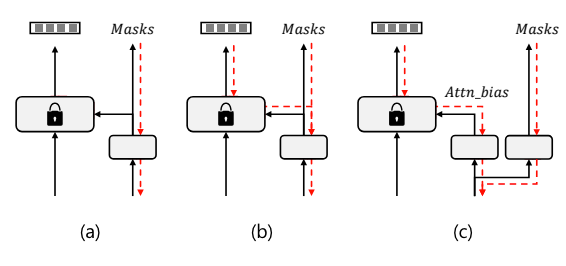
掩模预测头的设计选择。 (a) 单头和来自 CLIP 的阻塞梯度的两阶段训练; (b) 单头端到端训练; (c) 解耦头端到端训练。红色虚线表示训练期间的梯度流。
与其他两阶段框架不同,本文的方法是端到端的训练框架。
作者研究了其他两个框架之间的差异。由于注意力偏差分支必须通过 CLIP 进行训练,为了进行比较,在 CLIP 的自注意力层中使用 mask proposal 代替注意力偏差。如果来自 CLIP 的梯度被阻止,则该方法退化为两阶段框架,即掩模预测与 CLIP 识别隔离。否则,该方法是单头端到端训练框架,并且掩模预测是 CLIP 感知的。
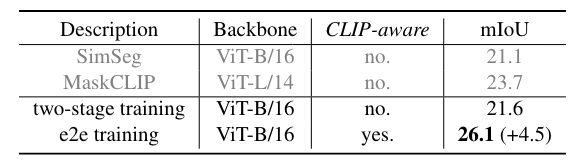
两阶段与端到端。这一显着改进证明了 CLIP 感知掩模预测的重要性。
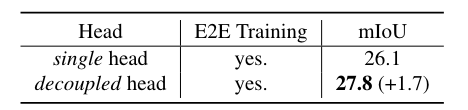
单头和解耦头的比较。只需很少的额外参数和触发器,解耦头就可以显着提高性能。所有模型都经过端到端训练。
单头设计意味着模型只有一个注意力头来处理掩码预测和识别。解耦头设计意味着模型在处理掩码预测和识别时,使用了多个注意力头,这些头之间的计算是解耦的。
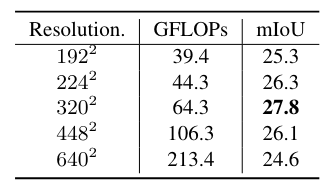
ViT-B/16 CLIP 模型输入分辨率的影响。改变 CLIP 输入分辨率,同时始终在侧面适配器网络中使用 640*640 图像。
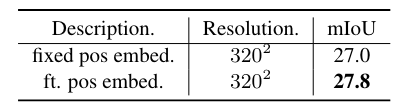
微调位置嵌入可以提高性能
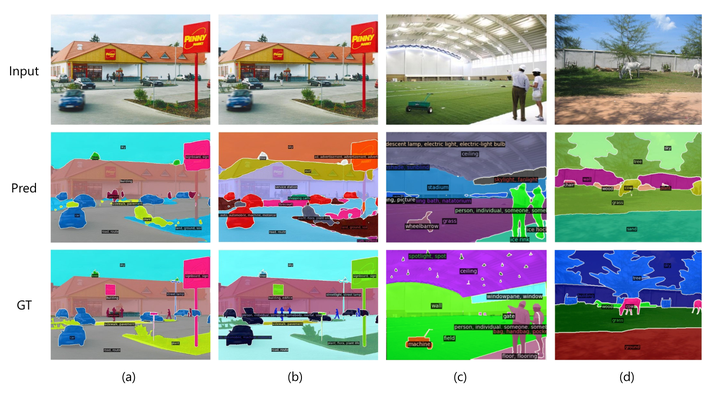
方法的定性结果。 (a) 和 (b) 是具有不同词汇表(分别为 ADE-150 和 ADE-847)的相同输入图像的结果
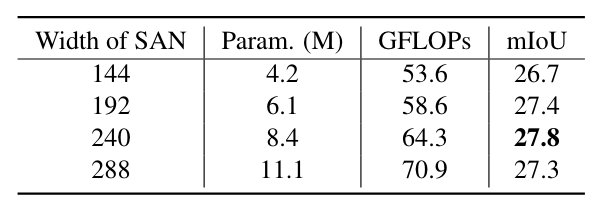
SAN容量的影响。代表模型中可训练参数的总数(以百万为单位)。
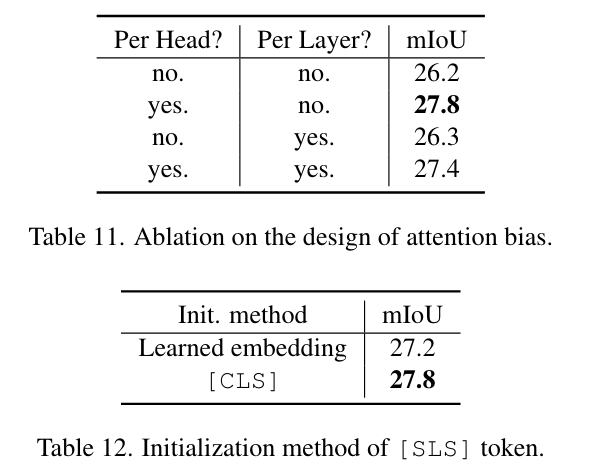
注意偏差设计的消融和[SLS]令牌的初始化方法
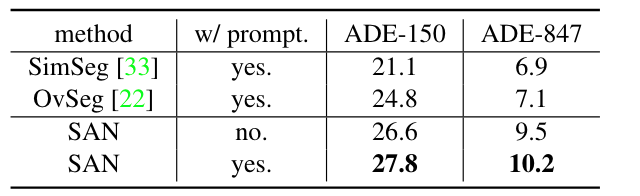
Prompt工程的效果。单个模板“{} 的照片”。用于不使用Prompt工程的模型。